【Google Cloud目線】Firestore のルールとインデックスの
書き方・使い方
📅 今日時点の情報 2026.02.17
📝 記事について: 本記事は、50近辺のくたびれたおっさん(貧乏)の筆者が、サイトやコードを作っていく際に気になったものをまとめたものです。内容の正確性については、必ず公式情報やデータソースをご確認ください。
Cloud Firestore のセキュリティルールとインデックスは、データの保護とクエリのパフォーマンスに直結します。ルールは「誰が何を読める・書けるか」を制御し、インデックスは複合クエリを可能にします。書き方・使い方・デプロイの基本を公式情報に沿ってまとめます。
この記事のポイント
- ルール:
matchでパスを指定しallow read, write: if 条件。request.auth・resource.data・request.resourceで認証・検証。 - ルールはフィルタではない: クエリの条件がルールと一致しないと拒否される。取得可能なドキュメントだけを返すクエリを書く。
- インデックス: 単一フィールドは自動。複合インデックスは等号+範囲・並び替えで必要。エラーのリンクから作成できる。
- デプロイ: コンソールまたは
firebase deploy --only firestore(firestore.rules/firestore.indexes.json)で反映。
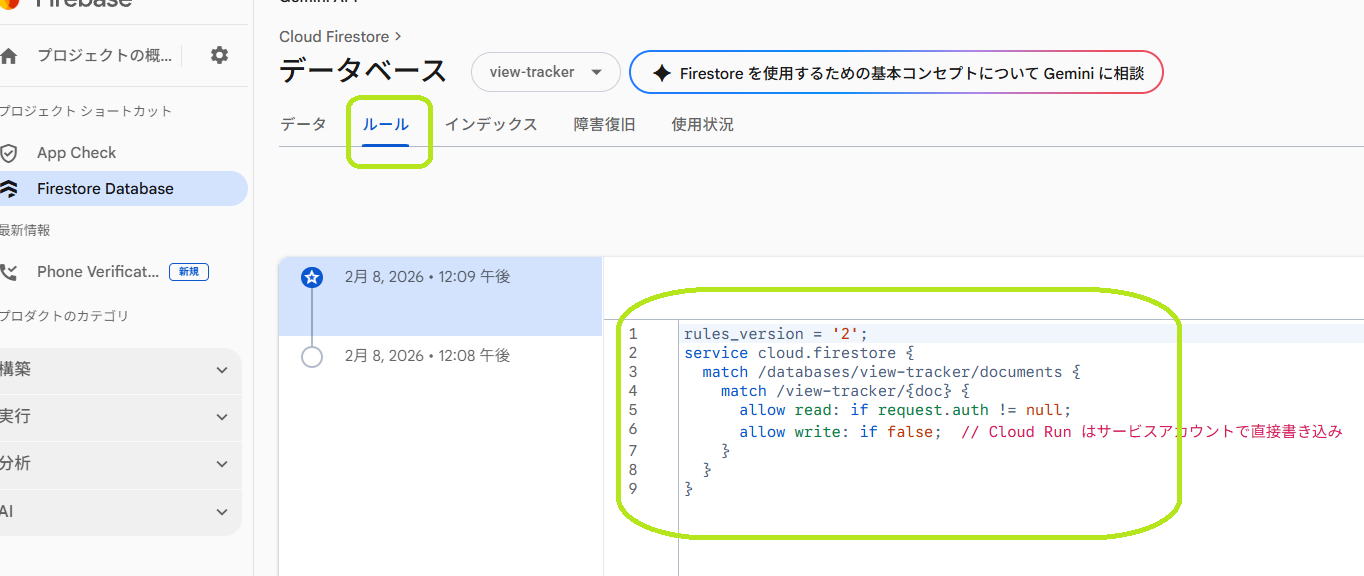
1. セキュリティルールの基本構造
ルールは4段の入れ子で書きます。上から「ルールのバージョン → Firestore サービス → データベース内のドキュメント範囲 → コレクションごとの許可条件」です。
- 1行目
rules_version = '2';… ルール言語のバージョン。コレクショングループクエリを使う場合は v2 必須。 - 2行目
service cloud.firestore { ... }… 「この中が Firestore 用のルール」というブロック。 - 3行目
match /databases/{database}/documents { ... }… どのデータベースのドキュメントに適用するか。{database}は (default) やカスタム DB 名が入る変数。 - 4行目以降
match /コレクション名/{doc} { allow read, write: if 条件; }… そのコレクション内のドキュメントに対する「読んでよい・書いてよい」の条件。{doc}はドキュメント ID が入る変数。
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
match /cities/{city} {
allow read, write: if request.auth != null;
}
}
}操作は read(= get+list)と write(= create+update+delete)にまとめて書けます。細かく分けたい場合は allow get, list: if ...; や allow create, update: if ...; のように指定します。
2. 認証とデータ検証
request.auth:クライアントの認証情報です。Firebase Authentication 利用時は request.auth.uid でユーザー ID を取得。「ログイン済みのみ許可」は request.auth != null、「自分のドキュメントだけ」は request.auth.uid == userId(match でキャプチャした変数)のように書きます。
resource.data:既存ドキュメントのフィールドです。読み取り・更新・削除の評価時に参照します。例:resource.data.visibility == 'public' で「public のドキュメントだけ読める」。
request.resource:書き込み後のドキュメントの状態です。create や update で「書ける内容」を検証するときに使います。例:request.resource.data.population > 0 で人口が正の値だけ許可。
他ドキュメントを参照するには get(/databases/$(database)/documents/コレクション/ID) や exists(...) が使えます。評価ごとの get/exists 呼び出し数には上限(単一リクエスト 10、複数ドキュメント 20)があるので注意してください。
3. ルールはフィルタではない
そのため、allow read: if resource.data.visibility == 'public' だけだと、collection("cities").get() は拒否されます(非 public が含まれる可能性があるため)。where("visibility", "==", "public").get() のように、クエリ条件で「public だけ返す」ことを保証すれば許可されます。クエリとルールの条件を一致させる設計にします。
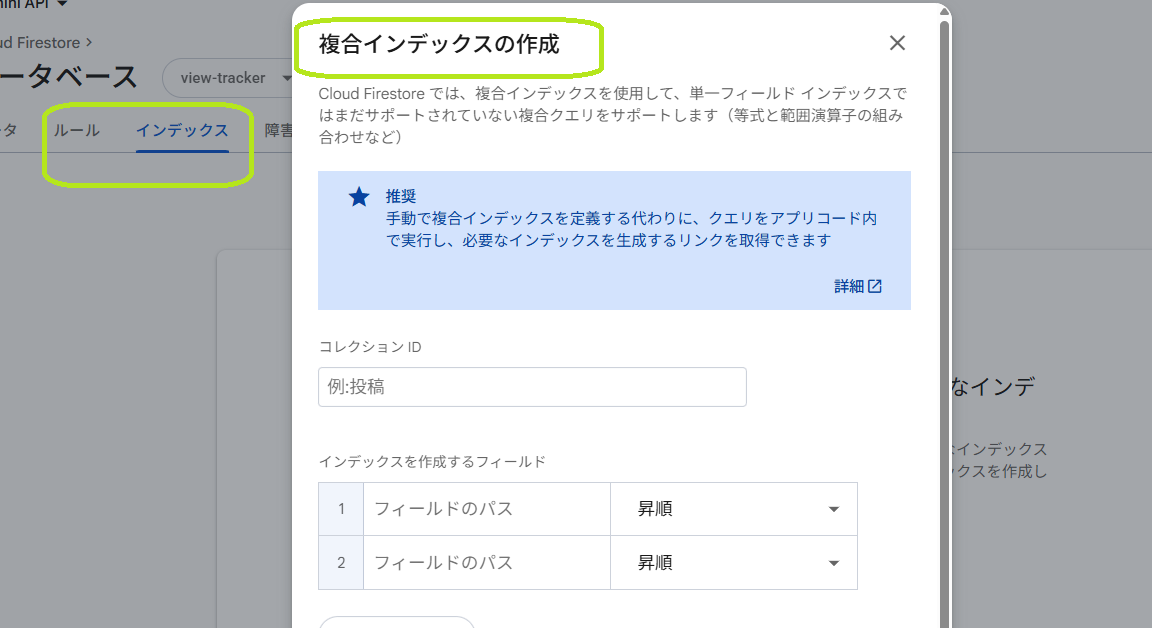
4. インデックス:単一と複合
Firestore はすべてのクエリにインデックスを使います。単一フィールドだけのクエリ(例:where("name", "==", "東京") だけ)は、そのフィールドのインデックスが自動で作られます。複合インデックスは自動では作られず、次のようなクエリで必須です。
複合インデックスがないとエラーになるクエリの例
以下のような書き方をすると、実行時にエラーになり、エラーメッセージに「インデックスを作成する」ための Firebase コンソールのリンクが含まれます。そのリンクを開くと、必要なコレクション・フィールド・昇順/降順がすでに入力されているので、「作成」で追加できます。
- 等価と範囲の組み合わせ … 例:
where("region", "==", "関東").where("population", ">", 100000)。1つは==、もう1つは</>などだと複合インデックスが必要。 - 等価+orderBy(別フィールド) … 例:
where("region", "==", "関東").orderBy("population", "desc")。where と orderBy で別のフィールドを指定していると複合インデックスが必要。 - 複数フィールドで orderBy … 例:
orderBy("region").orderBy("population", "desc")。orderBy を2つ以上使う場合も複合インデックスが必要。
逆に、where("name", "==", "東京") だけ、orderBy("createdAt", "desc") だけ、のように1フィールドだけのクエリは単一フィールドインデックスで足りるため、エラーにはなりません。複合インデックスを追加したあとは、構築に数分〜データ量に応じて時間がかかります。
5. firestore.indexes.json と CLI デプロイ
Firebase の公式ドキュメントでは、複数環境やチームで管理する場合は firestore.indexes.json にインデックス定義を書いてバージョン管理し、firebase deploy --only firestore でデプロイする方法が案内されています。firebase init firestore で雛形が生成されます。個人で1環境だけ使う分には必須ではなく、コンソールやエラー時のリンクから作成すれば十分なことが多いです。便利なのは、チームで同じインデックスを共有したいときや、dev/stg/prod のように複数環境の設定をそろえたいとき。そういう場合に「コードで定義してデプロイ」が役立ちます。
{
"indexes": [
{
"collectionGroup": "cities",
"queryScope": "COLLECTION",
"fields": [
{ "fieldPath": "region", "order": "ASCENDING" },
{ "fieldPath": "population", "order": "DESCENDING" }
]
}
]
}ルールは firestore.rules に記述し、同じ firebase deploy --only firestore でルールとインデックスをまとめてデプロイできます。コンソールで手動追加したインデックスは、ローカルの firestore.indexes.json にも反映しておくと差分が分かりやすくなります(firebase firestore:indexes で一覧取得可能)。
6. ルールのテストとデプロイ
Firebase コンソールの Firestore の「ルール」タブにはルールシミュレータがあります。認証あり/なしや特定のドキュメントパスで read/write をシミュレートでき、エディタ上のルールに対して実行されるので、本番に反映する前に確認すると安心です。ルールの反映には最大約 1 分、既存リスナーへの完全な反映には最大 10 分かかることがあります(公式・デプロイの説明)。
まとめると、ルールで「誰が何を」を制御し、インデックスで複合クエリを有効にします。ルールはクエリと整合させ、複合クエリはエラーリンクまたは firestore.indexes.json で事前に用意しておくのがおすすめです。詳細はセキュリティルール(公式)とインデックス(公式)を参照してください。
Artist's Perspective
「ルールもインデックスも、GCP の Cloud Run から実際に書き込んで、ちゃんと動くかテストしてました~~。連携技として、スケジュールで Cloud Run を実行して、条件をいろいろ変えながら DB に書き込んでみる、というやり方です。面白いのが、Web の管理画面でデータベースの中身がリアルタイムに近い形で見えること。ちょっと感動ですよね。」
「ルールやインデックスは、実際にデータベースを使いながら確かめていくと、エラーで弾かれたりするんですよ。その都度ルールを直したり、エラーに出るリンクからインデックスを追加したり……。おっさん、トライ&エラーで覚えていった感じです。」
「まだ基本的なところだけですが、リレーショナルデータベースとか複雑な構造(本で読んだくらいですが笑)、これ使えばできそうですね。」
データソース・参考リンク
本記事は以下の情報源を参考にしています。内容の正確性については、必ず元のデータソースをご確認ください。